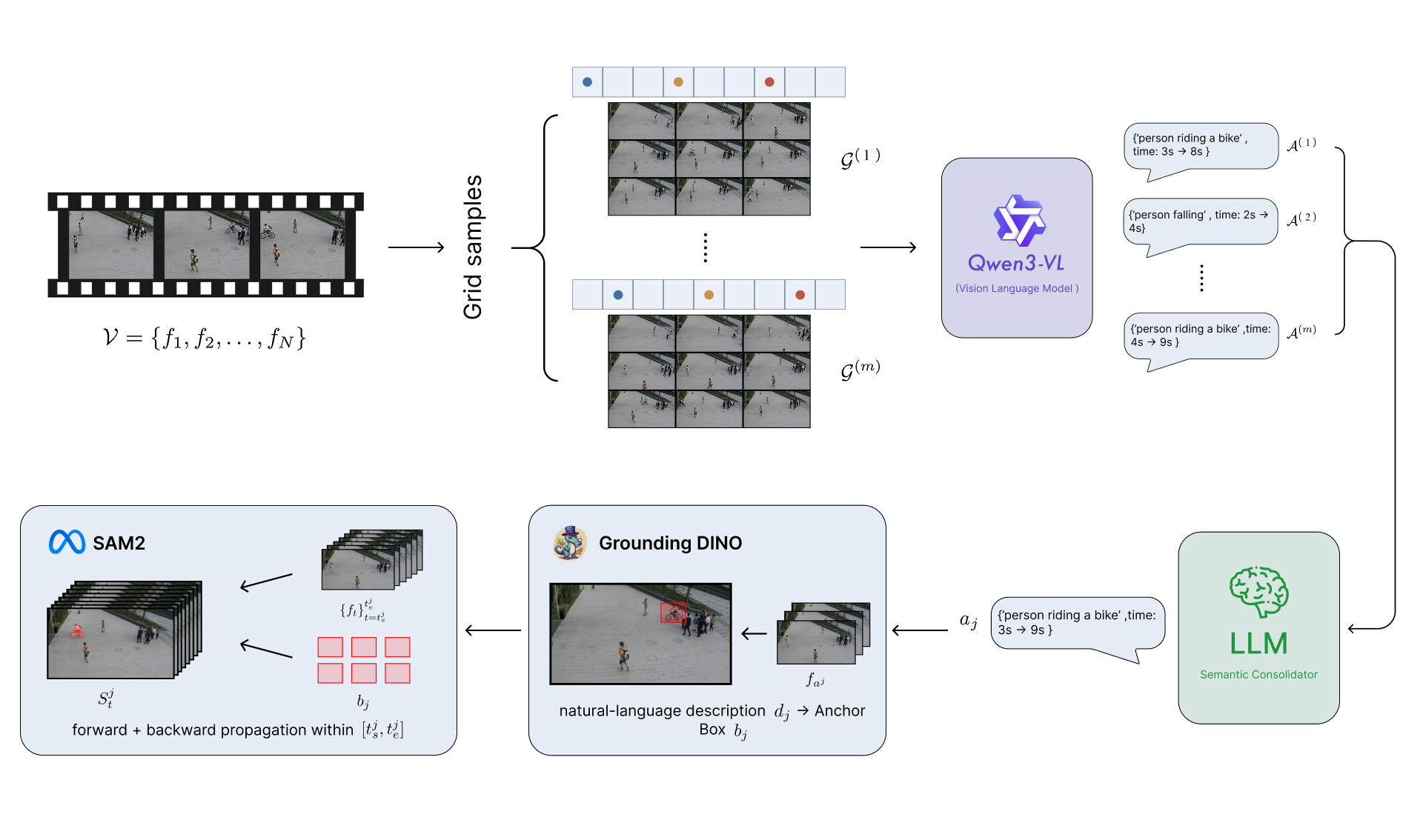
Vision-Language Models (VLMs) are powerful open-set reasoners, yet their direct use as anomaly detectors in video surveillance is fragile: without calibrated anomaly priors, they alternate between missed detections and hallucinated false alarms. We argue the problem is not the VLM itself but how it is used. VLMs should function as anomaly proposers, generating open-set candidate descriptions that are then grounded and tracked by purpose-built spatial and temporal modules. We instantiate this propose-ground-propagate principle in GridVAD, a training-free pipeline that produces pixel-level anomaly masks without any domain-specific training. A VLM reasons over stratified grid representations of video clips to generate natural-language anomaly proposals. Self-Consistency Consolidation (SCC) filters hallucinations by retaining only proposals that recur across multiple independent samplings. Grounding DINO anchors each surviving proposal to a bounding box, and SAM2 propagates it as a dense mask through the anomaly interval. The per-clip VLM budget is fixed at M+1 calls regardless of video length, where M can be set according to the proposals needed. On UCSD Ped2, GridVAD achieves the highest Pixel-AUROC (77.59) among all compared methods, surpassing even the partially fine-tuned TAO (75.11), and outperforms other zero-shot approaches on object-level RBDC by over 5×. Ablations reveal that SCC provides a controllable precision-recall tradeoff: filtering improves all pixel-level metrics at a modest cost in object-level recall. Efficiency experiments show GridVAD is 2.7× more call-efficient than uniform per-frame VLM querying while additionally producing dense segmentation masks.
GridVAD follows a propose–ground–propagate decomposition. A VLM proposes free-form anomalies over stratified frame grids; a Self-Consistency Consolidation step suppresses hallucinations; Grounding DINO and SAM2 then localise and propagate each detection. No stage requires anomaly supervision.
Each clip shows the input video alongside GridVAD's predicted pixel-level anomaly masks across both benchmarks.
Table 1. Quantitative comparison on UCSD Ped2. Baseline numbers are transcribed from the TAO paper; our results are in the last row. Bold = best, underline = second best.
| Method | Pixel-AUROC ↑ | Pixel-AP ↑ | Pixel-AUPRO ↑ | Pixel-F1 ↑ | RBDC ↑ | TBDC ↑ |
|---|---|---|---|---|---|---|
| AdaCLIP (Fully fine-tuned) | 53.06 | 4.97 | 50.66 | 11.19 | 12.3 | 15.5 |
| AnomalyCLIP (Fully fine-tuned) | 54.25 | 23.73 | 38.59 | 7.48 | 13.1 | 21.0 |
| DDAD (Fully trained) | 55.87 | 5.61 | 15.12 | 2.67 | 18.01 | 13.29 |
| SimpleNet (Fully trained) | 52.49 | 20.51 | 44.05 | 10.71 | 51.18 | 27.75 |
| DRAEM (Fully trained) | 69.58 | 30.63 | 35.78 | 10.89 | 44.26 | 70.64 |
| TAO (Partially fine-tuned) | 75.11 | 50.78 | 72.97 | 64.12 | 83.6 | 93.2 |
| AdaCLIP (Zero-shot) | 51.02 | 1.32 | 33.98 | 2.61 | 5.8 | 10.6 |
| AnomalyCLIP (Zero-shot) | 51.63 | 21.20 | 36.34 | 5.92 | 7.5 | 11.2 |
| GridVAD (Ours, Zero-shot) | 77.59 | 38.53 | 66.82 | 42.09 | 38.96 | 37.70 |
@inproceedings{paper, title = {GridVAD: Open-Set Video Anomaly Detection via Spatial Reasoning over Stratified Frame Grids}, author = {Mohamed Eltahir, Ahmed O. Ibrahim, Obada Siralkhatim, Tabarak Abdallah, Sondos Mohamed}, booktitle = {arXiv}, year = {2026}, url = {https://arxiv.org/abs/XXXX.XXXXX} }